
EECS 281: Project 4 - Drone Delivery
Due Monday, December 8 at 11:59pm
Overview
You will be given a graph as a collection of x-y coordinates (vertices) and a rule or rules about how they are connected (edges). This project has three parts:
- Part A: Calculate a Minimum Spanning Tree (MST) to find the subset of edges that represent lowest edge weight cost to connect all vertices.
- Part B: Research and implement an algorithm to approximate a solution to the Travelling Salesperson Problem (TSP); the solution need not be optimal, but it must be “close enough” and “fast enough” to satisfy the autograder.
- Part C: Calculate the weight of an optimal TSP solution, using a branch and bound algorithm.
Project Goals
- Understand and implement MST algorithms
- Be able to determine whether Prim’s Algorithm or Kruskal’s Algorithm is more efficient for a particular scenario
- Understand and implement a Branch and Bound algorithm
- Develop a fast and effective bounding algorithm for the TSP
- Explore various heuristic approaches to quickly achieving a nearly-optimal solution
- Research online to identify, learn, and implement various “TSP heuristics”
- Use a graph visualization tool to help with debugging
Backstory (for fun)
You’ve decided to start a company to handle on-campus deliveries of items via drone. Not just at UM, you’re developing software to sell so that people at other campuses can set up their own drone delivery service!
There are two types of drones under development, used for three different purposes:
Drone Type I is a drone that moves ten times as fast as other drones. However, these drones require drone director beacon installations along each path so that their rapid flight can be properly controlled. The cost of installing these beacons are directly proportional to the distance of the desired path, and clients will want to minimize the cost of beacons.
Drone Type II is a regular drone similar to competing products. The drone’s energy usage is directly proportional to the distance it travels.
There are currently three types of clients (A, B, and C) that are interested in your drones, and your task will vary based on the client type. This is described further in detail below.
To be clear: these scenarios are separate; the program will create a plan for one or the other, but not both in the same run (though you may find that algorithms from one mode help with another mode).
In this project, your output does not need to be exactly the same as ours to be correct. As long as it provides a valid answer, and follows the rules for formatting output, it can be in a different order or use different edges, and still be correct.
Common Project Elements
The specific parts of the project will be described in detail below, but there are some common elements that will be used in all parts of the project.
Command Line Arguments
Your program, drone, should take the following case-sensitive command line options:
-m,--mode {MST|FASTTSP|OPTTSP}- MST: Find the minimum spanning tree (MST) of the map
- FASTTSP: Find a fast, but not necessarily optimal, solution to the TSP
- OPTTSP: Find the optimal solution to the TSP
This command line option is required and has a required argument. If it is not properly included, print a useful error message to standard error (cerr) and exit(1). Program output format is dictated by given mode.
All of modes share the same input format, but only one mode will be tested at a time. Your program should be able to handle all three modes, but each call to your program will only test one mode. You may find that one mode will be helpful when implementing another mode, but you need only supply one final answer for each mode.
-h,--help
Print a short description of this program and its arguments and exit(0).
Valid examples of how to execute the program:
$ ./drone --mode MST (OK, but you must type the input by hand)
...
$ ./drone -h < inputFile.txt (OK, -h happens before we realize there’s no -m)
...
$ ./drone -m OPTTSP < inputFile.txt (OK, redirects input from a file on disk)
...
When input redirection is used it is handled by the shell, and it neither affects nor can be seen by the command line. Redirecting input sends the contents of the file specified to the program via cin. You should not have to modify your code to allow this to work; the operating system will handle it.
We will not be specifically error-checking your command-line handling, however we expect that your program conforms with the default behavior of getopt_long(). Incorrect command-line handling may lead to a variety of difficult-to-diagnose problems.
Input File Format
On startup, your program reads graph vertices from standard input (cin). These vertices are delivery locations (to go along with the backstory described above). The map can be represented as a cartesian plane, and you will be given an integer, \(N\), denoting how many vertices are in the graph. This will be followed by \(N\) ordered pairs of integers describing points on the Cartesian plane, one per line, delimited by a single space.
Vertices are identified by integer indices which correspond to the order in which they are read in (the first vertex is vertex 0, the second vertex is vertex 1, etc.). The input will always be well-formed and conform to this format, so there is no need to error check. There may be additional blank lines, but only at the end of the file.
5
6 1
2 3
-5 -4
-1 6
0 -1
For Part A, there will always be at least two points. For Parts B and C, there will always be at least 3 points.
Map Areas
The map will be divided into three areas: medical campus (QIII in the Cartesian plane), main campus (QI, QII, and QIV), and the border between them (origin plus negative x- and y-axes). Delivery locations can appear in any of these areas, and can only be in one area. When a location’s area is important (Part A), it can be stored with its coordinates if done efficiently. Choosing to do so is optional and a great example of a trade-off between space and time, where the additional space used to store the area of a location can help save time when evaluating the areas of two locations while calculating the distance between them.
Pro tip: When categorizing vertices, remember the analysis of binary search, where the earliest comparison was used to gain the largest amount of information, and the least likely outcome was saved for last without any specific conditionals needed. This is a two-dimensional graph, so multiple comparisons and logical combinations are needed, but the same idea applies and can be used to simplify your code.
Ask, “What single comparison can I make that will give me the most information about the location of a vertex?” and “What is the least likely outcome of that comparison?”. The answers to these questions will help you determine the order in which to make comparisons, and how to combine them.
The sample above can be visualized as in the figure below, where the numbers shown are the location indices and the blue line indicates the border which separates the medical campus from the main campus. Location 2 is on the medical campus, location 4 is on the border, and the rest of the locations are on the main campus.
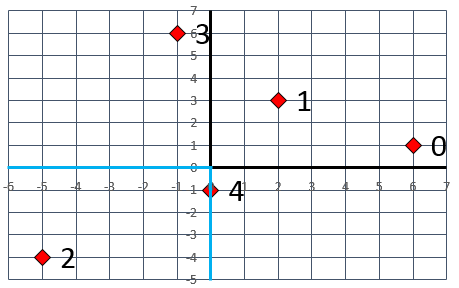
There is more than one way to represent this configuration internally in your program, and this will affect your runtime. Choose your data structures wisely!
Output and the Autograder
In this project, your output does not need to be exactly the same as ours to be correct. As long as your output provides a valid tree- or path-weight and follows formatting rules, it can be a different tree or path and still be correct. Alternatively, your solution may find a tree or path identical to the one on the autograder and print it in a different order, and still be correct. Anything that is judged as correct will be given full points and not be penalized for being different from the autograder.
Distance Calculations
To calculate the distance between two points use Euclidean Distance, \(d = \sqrt{(x_1 - x_2)^2 + (y_1 - y_2)^2}\), and store distances as doubles. Please be very careful with rounding errors in your distance calculations; the autograder will allow you a 0.01 margin of error to account for rounding, but you should only round values during output, not during intermediate steps.
Pro tips:
- Using
pow()to calculate the square of a number is not necessary, and can be avoided by using the multiplication operator. For example,pow(x, 2)can be written asx * xwhich executes faster. - Be thoughtful about intermediate calculations which may overflow the range of an
intbefore they are stored in the outputdouble. sqrt()is a relatively slow function, and may be avoided if you consider the following: if \(a < b\) then \(\sqrt{a} < \sqrt{b}\). The same cannot be said when sums are involved, so \(a + b < c + d\) does not guarantee that \(\sqrt{a} + \sqrt{b} < \sqrt{c} + \sqrt{d}\), so should not be used.
When you are route finding (in Parts B and C), you can travel directly between any two locations, regardless of area; in other words, you may ignore the border constraint.
Part A: MST mode
In this mode you will devise a connected network of high-speed drone beacons that minimizes the total length of connections needed (MST). You may use any MST algorithm to connect all the locations. Hint: Unless you want to implement both and compare, think about the nature of the graph (how many vertices and edges does it have?). You are free to adapt code from the lecture slides to fit this project, but you will want to carefully think about the data structures necessary to do each part (storing unnecessary data can go over memory limits). Your program must always generate one valid MST for each input.
When connecting locations in Part A, easy connections are only allowed between two locations in the same area, or between two locations when at least one of them is on the border (see Map Areas). Travel to the medical campus from the main campus must go through a location on the border, and the border must also be used to travel from the main campus to the medical campus. For example, you are not allowed to travel directly from (-5, -4) to (6, 1). You must first travel from (-5, -4) to (0, -1), and then from (0, -1) to (6, 1).
For the sake of simplicity, assume any travel between two main campus locations that crosses over some medical campus area will be allowed. The border restriction only prevents takeoff from and landing in different campuses. The example below shows two validly connected land locations, A and B.
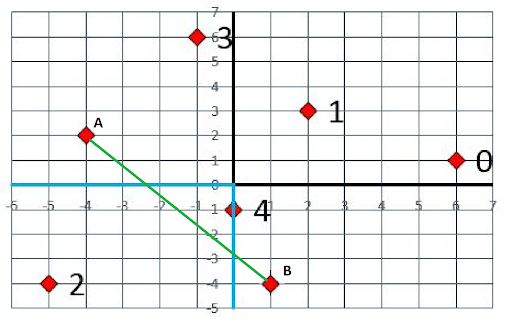
Part A Distances
The distance between any two locations in the same area, or between any location and a location on the border, is the Euclidean distance between the two locations. The distance between any location on the main campus and any location in the medical campus is effectively infinite, since you cannot travel directly between the two areas.
Part A Graph Representation
MST Mode may have a minimum of two vertices but the autograder will also run tests with tens of thousands of locations. A distance matrix with \({\vert V\vert}^2\) double values is not guaranteed to fit in memory. Since you cannot afford enough space that would allow look up of edge weights, you will have to calculate the distances between locations whenever you need them.
Part A Output Format
For the MST mode, you should print the total weight of the MST you generate by itself on a line; this weight is the sum of the weights of all edges in your MST (in terms of Euclidean distance). You should then print all edges in the MST. All output should be printed to standard output (cout).
The output should be of the format:
weight
node node
node node
......
Here, node is a location index corresponding to the vertices of the MST, and a pair of nodes on a given line of the output describes an edge in the MST from the first node to the second. The weight should be formatted as a double (2 decimal point precision is enough - see Appendix A), and the node numbers should all be integer values when printed. For example, given the example input file above, your MST mode output might be:
19.02
0 1
2 4
1 3
1 4
You should also always print the pairs of vertices that describe an edge such that the index on the left has a smaller integer value than the index on the right. In other words:
1 2
is a possible valid edge of output, but
2 1
is not valid output.
If it is not possible to construct an MST for the given locations because there are locations both on the medical campus and on the main campus, with no border locations, your program should print the message “Cannot construct MST” to cerr and exit(1).
Part B: FASTTSP Mode
In this mode, you will figure out how to send a single drone to every delivery location and then return to the starting location. You will be implementing solutions to the Travelling Salesperson Problem (TSP). The route will always start at the first location in the file (index 0), visit every other location exactly once, and return to the starting point. You must solve the TSP and choose paths to locations so as to minimize the total distance travelled.
In FASTTSP mode there can be large numbers of possible locations to visit, finding an optimal method for visiting all of them may be too slow, and the sun may cool before you are able to complete your task. You can use heuristics instead to find nearly-optimal tours. A heuristic is a problem-solving method (an algorithm) that can produce a good answer that is not necessarily the best answer. For example, you can skip a branch speculatively rather than waiting to know for a fact that it can be skipped. There are many other simple heuristic techniques, such as starting with a random tour and trying to improve it by small changes. Do some online searching for “TSP heuristics”. There are several types, some easier to implement, some with better path lengths, some both. Make sure that you choose and implement an algorithm that is \(O(n^2)\).
You should produce a solution to the Travelling Salesperson Problem (TSP) that is a close approximation to the optimal tour length. Given the time constraint, you will be unable to reliably find the optimal solution, though in lucky situations (depending on the graph and the algorithm chosen) the optimal solution my be found occasionally.
You are allowed to use any combination of algorithms for this section that we have covered in class, including the MST algorithm you wrote for Part A.
You will need to be creative when designing your algorithms for this section. You are free to implement any other algorithm you choose, so long as it meets the time and memory constraints. However, you should not use any advanced algorithms or formulas (such as Simulated Annealing, Genetic Algorithms and Tabu search - they are too slow) that are significantly different from what has been covered in class. Instead, creatively combine the algorithms that you already know and come up with concise optimizations. Your heuristic will very likely be greedy in some way, but there are different ways to be greedy!
Part B Distances
The distance between any two locations is the Euclidean distance between the two locations.
The length of a tour is defined as the sum of all pairwise distances travelled - that is, the sum of the lengths of all edges taken.
Part B Graph Representation
FASTTSP Mode may have a minimum of three vertices but the autograder will also run tests with tens of thousands of locations. A distance matrix with \({\vert V\vert}^2\) double values is not guaranteed to fit in memory. Since you cannot afford enough space that would allow look up of edge weights, you will have to calculate the distances between locations whenever you need them.
Part B Output Format
You should begin your output by printing the overall length of your tour on a line. On the next line, output the nodes in the order in which you visit them. The initial node should be the starting location index and the last node should be the location number directly before returning back to the 0-th location. The nodes in your tour should be printed such that they are separated by a single space. There can be a space after the last location listed. All output should be printed to standard output (cout).
For example, if given the input file above, your program could produce either of the following correct outputs:
31.64
0 4 2 3 1
or
31.64
0 1 3 2 4
Part C: OPTTSP Mode
See Part B for a description of the TSP problem. In this mode, you will be implementing a solution to the TSP that is guaranteed to be optimal. You will use genPerms() to find a route that will always start at location index 0, visit every other location exactly once, and return to the starting point. You must solve the TSP and choose edges to connect locations so as to minimize the total distance travelled.
To find an optimal tour, you could start with the brute force method of exhaustive enumeration that evaluates every tour and picks a smallest tour. By structuring this enumeration in a clever way, you could determine that some branches of the search cannot lead to optimal solutions. For example, you could compute lower bounds on the length of any full tour that can be found in a given branch. If such a lower bound exceeds the cost of a full solution you have found previously, you can skip this branch as hopeless. If implemented correctly, such a branch-and-bound method should always produce an optimal solution. It will not scale as well as sorting or searching algorithms do for other problems, but it should be usable with a small number of locations. Clever optimizations (identifying hopeless branches of search early) can make your algorithm a hundred times faster. Drawing TSP tours on paper and solving small location configurations to optimality by hand should be very useful. Remember that there is a tradeoff between the time it takes to run your bounding function and the number of branches that bound lets you prune.
MAKE SURE that you use the version of genPerms() that uses swap() and a single container, rather than the two-container version (stack & queue) that is much slower.
Given an input set of \(N\) locations defined by integer coordinates, your job is to produce an optimal tour using a branch-and-bound algorithm. Your program should always produce the shortest possible tour as a solution, even if computing that solution is time-consuming. You will be given a 35-second cpu time limit to generate your solution. If your program does not produce a valid solution, it will fail the test case. Your solution will also be judged by time and space budgets as per previous projects.
Part C Distances
Same as Part B Distances.
Part C Graph Representation
OPTTSP Mode may have a minimum of three vertices but, due to time constraints, the autograder will only run tests with a few dozen locations. A distance matrix with \({\vert V\vert}^2\) double values will fit in memory, so you can afford enough space to allow precalculation of all edge weights. However, in testing this is not significantly faster than calculating them as needed, and in some cases can make it harder to code. We’ve coded this both with and without a distance matrix, and both versions earned full points.
Part C Output Format
Same as Part B Output Format.
Testing and Debugging
Part of this project is to prepare several test files that will expose defects in buggy solutions - your own or someone else’s. As this should be useful for testing and debugging your programs, we recommend that you first try to catch a few of our intentionally-buggy solutions with your test files, before completing your solution. The autograder will also tell you if one of your own test files exposes bugs in your solution.
Each test that you submit should consist of an input file. When we run your test files on one of intentionally-buggy project solutions, we compare the output to that of a correct project solution. If the outputs differ, the test file is said to expose that bug.
Test files should be named test-n-MODE.txt where \(1 \le n \le 10\). The autograder’s buggy solutions will run your test files in the specified MODE. The mode must be MST, FASTTSP, or OPTTSP.
Your test files may have no more than 10 coordinates in any one file. You may submit up to 10 test files (though it is possible to get full credit with fewer test files). The tests the autograder runs on your solution are NOT limited to 10 coordinates in a file; your solution should not impose any size limits (as long as sufficient system memory is available).
Submitting to the Autograder
Do all of your work (with all needed source code files, as well as test files) in some directory other than your home directory. This will be your “submit directory”. Before you turn in your code, be sure that:
- Every source code and header file contains the following project identifier in a comment at the top of the file:
// Project Identifier: 1761414855B69983BD8035097EFBD312EB2517F0 - The Makefile must also have this identifier (in the first TODO block)
- You have deleted all .o files and your executable(s). Typing ‘make clean’ shall accomplish this.
- Your makefile is called Makefile. Typing
make -R -rbuilds your code without errors and generates an executable file calleddrone. The command-line options -R and -r disable automatic build rules, which will not work on the autograder. - Your Makefile specifies that you are compiling with the gcc optimization option -O3. This is extremely important for getting all of the performance points, as -O3 can speed up code by an order of magnitude.
- Your test files are named test-n-MODE.txt and no other project file names begin with test. Up to 10 test files may be submitted. The “mode” portion of the filename must be MST, OPTTSP or FASTTSP.
- The total size of your program and test files does not exceed 2MB.
- You don’t have any unnecessary files (including temporary files created by your text editor and compiler, etc) or subdirectories in your submit directory (i.e. the .git folder used by git source code management).
- Your code compiles and runs correctly using the g++ compiler. This is available on the CAEN Linux systems (that you can access via login-course.engin.umich.edu. Even if everything seems to work on another operating system or with different versions of GCC, the course staff will not support anything other than GCC running on CAEN Linux.
Turn in all of the following files:
- All your .h and/or .cpp files for the project
- Your Makefile
- Your test files
You must prepare a compressed tar archive (.tar.gz file) of all of your files to submit to the autograder. One way to do this is to have all of your files for submission in one directory. In this directory, run
$ tar -czvf submit.tar.gz Makefile *.cpp *.h test-*.txt
a Makefile
a main.cpp
...
This will prepare a suitable file in your working directory. Alternatively, the 281 Makefile has useful targets fullsubmit and partialsubmit that will do this for you. Use the command make help to find out what else it can do!
Submit your project files directly to one of the autograders at https://eecs281ag.eecs.umich.edu/. When the autograders are turned on and accepting submissions, there will be an announcement on Piazza. The autograders are identical and your daily submission limit will be shared (and kept track of) between them. You may submit up to four times per calendar day (more during the Spring). For this purpose, days begin and end at midnight (Ann Arbor local time). We will count only your best submission for your grade. If you would instead like us to use your LAST submission, see the autograder FAQ page, or use this form.
Please make sure that you read all messages shown at the top section of your autograder results! These messages often help explain some of the issues you are having (such as losing points for having a bad Makefile or why you are segfaulting). Also be sure to check if the autograder shows that one of your own test files exposes a bug in your solution (at the bottom). Search the autograder results for the word “Hint” (without quote marks) for potentially useful information.
Libraries and Restrictions
We highly encourage the use of the STL for this project, with the exception of several prohibited features. Do not use:
- The C++11 regular expressions library
- The STL thread/atomics libraries (which spoil runtime measurements)
- Shared or unique pointers.
- Other libraries (e.g., boost, pthreads, etc).
Grading
80 points – Your grade will be derived from correctness and performance (runtime). This will be determined by the autograder. On this project we expect a much broader spread of runtimes than on previous projects. As with all projects, the test cases used for the final grading are likely to be different.
10 points – Your program does not leak memory. Make sure to run your code under valgrind before each submit. This is also a good idea because it will let you know if you have undefined behavior (such as reading an uninitialized variable), which may cause your code to crash on the autograder.
10 points – Student test file coverage (effectiveness at exposing buggy solutions).
Runtime Quality Tradeoffs
In this project there is no single correct answer (unlike previous projects). Accordingly, the grading of your problem will not be as simple as a ‘diff’, but will instead be a result of evaluating your output. For example, if we gave you a square for Part A, you might choose any 3 of the 4 edges, and print them in any order, meaning there are 24 possible correct output files!
Particularly for Part B, we expect to see greater variation in student output. Part B asks you to solve a hard problem, and with the given time constraints, we don’t actually expect your output to be optimal for all cases. The quality of your solutions may even vary from case to case. We want you to quickly produce solutions that are close to optimal. This inevitably creates tradeoffs between solution optimality and runtime.
You may find it useful to implement more than one algorithm or heuristic that you use in Part B, and do some testing plus use the autograder to determine which works the best.
Your grade for Part B will be determined based on how close you are to the best solution, computed as a percentage.
Copyright Notice
This project, its Makefile, and solution algorithm are protected by U.S. and International copyright laws. Reproduction and/or distribution of its content without written permission of the original author is prohibited.
Copyright © 2023 EECS 281 and the Regents of the University of Michigan.